
 Open Exchange
Open ExchangeDuas Grandes Mudanças para a Ferramenta de Código Aberto TestCoverage: Suporte a Python Embutido e uma Nova Interface de Usuário
Python Embutido
Anteriormente, o TestCoverage conseguia rastrear a cobertura de testes unitários apenas para códigos escritos em ObjectScript. Ele ignorava o código escrito em outras linguagens, como Python, nas estatísticas de cobertura.

À medida que mais e mais código de aplicativo IRIS está sendo escrito em Python Embutido em vez de apenas ObjectScript, é fundamental que o TestCoverage possa incluir os resultados de cobertura para o código Python Embutido . Clientes (através dos issues do TestCoverage no GitHub), bem como outros na InterSystems, expressaram interesse em ver o suporte ao Python Embutido.

O usuário ainda instala e executa o TestCoverage da mesma forma que antes, conforme descrito no TestCoverage GitHub. TOs resultados de cobertura para código Python Embutido agora são incluídos nas estatísticas de cobertura agregadas, bem como na coloração individual das linhas, como exibido no exemplo acima.
Por baixo do capô, a cobertura do Python Embutido é rastreada usando o tracer sys.settrace do Python, independentemente do %Monitor.System.LineByLine do ObjectScript, e então os resultados são combinados e exibidos juntos. Isso pode causar pequenas discrepâncias em quais linhas são marcadas como executáveis (ou seja, podem ser executadas). Por exemplo, na imagem acima, o Python considera a instrução elif como executável, mas o ObjectScript não considera a instrução ElseIf como executável. No fim das contas, qualquer linha de código marcada em vermelho não foi coberta, e qualquer linha de código marcada em verde ainda foi coberta; isso apenas afeta ligeiramente quais linhas de código ignoramos, o que não causa nenhum problema.
Nova Interface de Usuário do TestCoverage
A interface de usuário anterior do TestCoverage era uma antiga Zen UI que não mostrava muitas das estatísticas úteis que o TestCoverage rastreava. Além disso, o TestCoverage só podia ser executado a partir da linha de comando.
Para resolver esses problemas, criamos uma nova Angular UI baseada no isc.perf.ui, a interface de usuário existente para interagir com o Line-By-Line Monitor (^%SYS.MONLBL). O aplicativo web vem com uma API REST e uma conexão WebSocket para recuperar dados do servidor IRIS. Ele também corrige a autenticação de usuário anterior para o isc.perf.ui, de modo que agora ele usa o login/logout padrão do IRIS. Isso também está publicamente disponível no Open Exchange, sob o nome isc-perf-ui. Abaixo estão algumas das novas funcionalidades e usos da interface de usuário.
Instalação
Existem algumas etapas adicionais para instalar o isc.perf.ui se você quiser usar os novos recursos do TestCoverage. Apenas no Windows, você precisa habilitar o protocolo WebSocket do IIS. Em qualquer sistema operacional, você precisa conceder a um usuário específico (geralmente CSPSystem) uma permissão de recurso (geralmente %DB_User) no portal de gerenciamento do IRIS. Essas etapas são descritas na página do GitHub do isc-perf-ui..
Página de Cobertura de Teste
Na página de Cobertura de Teste, você pode selecionar os parâmetros com os quais deseja executar o TestCoverage em seus testes de unidade.
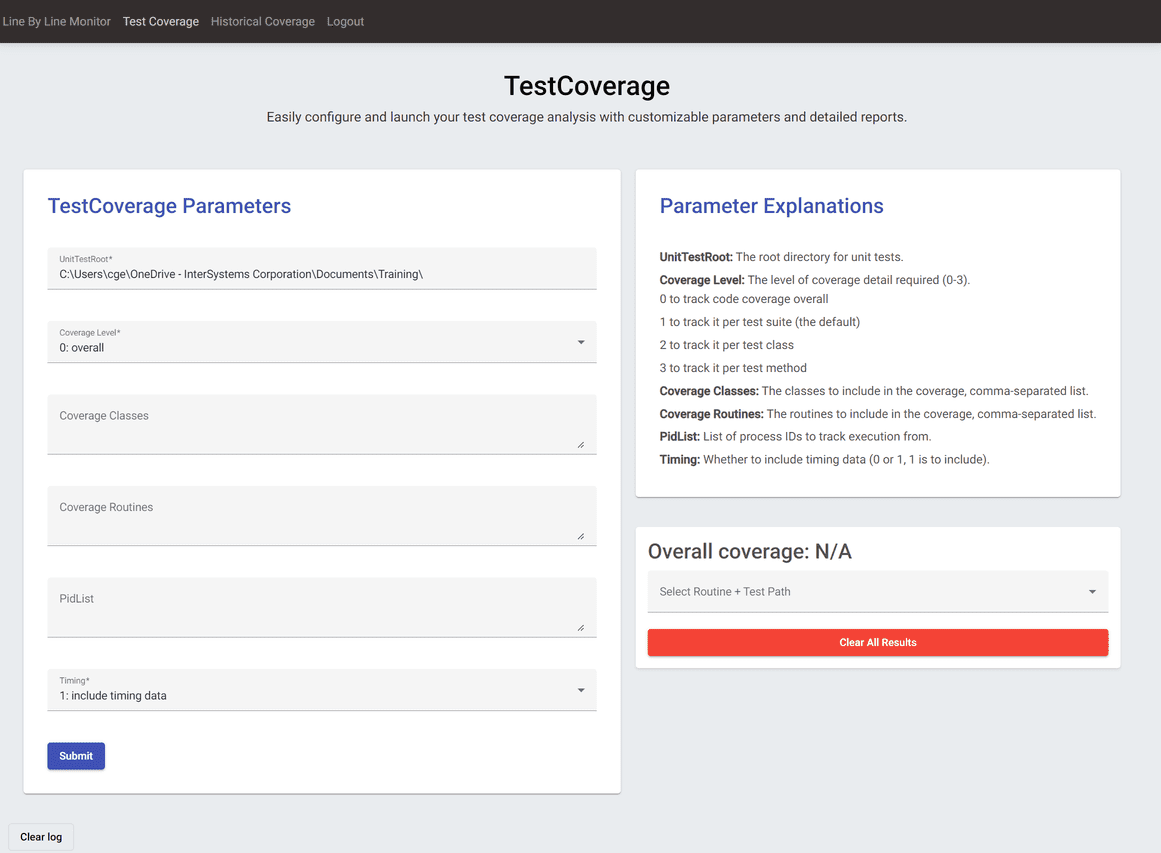
As explicações dos parâmetros incluem descrições do que cada um deles controla. Você também pode clicar em uma caixa de entrada para ver um valor de exemplo, e há validação de entrada para garantir que seus dados estejam em um formato válido.
Depois de clicar em "enviar", a chamada para executar o TestCoverage será iniciada, e você verá o progresso ao vivo dos seus testes de unidade no registro na parte inferior da página.
Após a conclusão da execução dos testes, o menu suspenso à direita deve abrir com uma lista de combinações de rotina e caminho de teste, bem como a porcentagem geral de cobertura do seu código e o link para os próprios resultados dos testes de unidade.
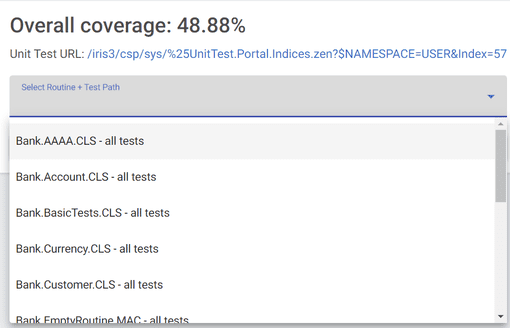
Clique em qualquer um deles para ser levado à página de resultados de cobertura daquela rotina, dentro do diretório de teste de unidade.
Aqui, você consegue ver quais linhas de código foram cobertas pelos seus testes de unidade, de acordo com o TestCoverage. Há também métricas adicionais, como TempoTotal, que monitora a quantidade de tempo que o código passou em uma determinada linha, do início ao fim da execução.
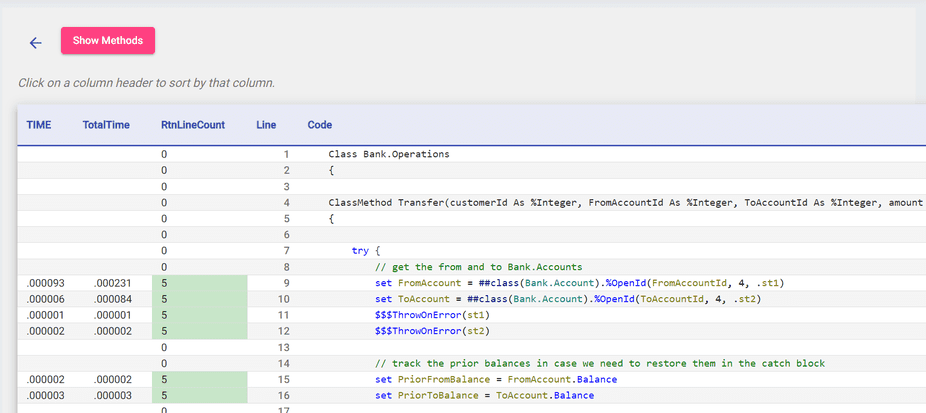
Você pode ordenar ainda mais em ordem crescente ou decrescente clicando nas setas ao lado dos cabeçalhos; essa é uma forma útil de ver quais linhas de código demoram mais para executar.
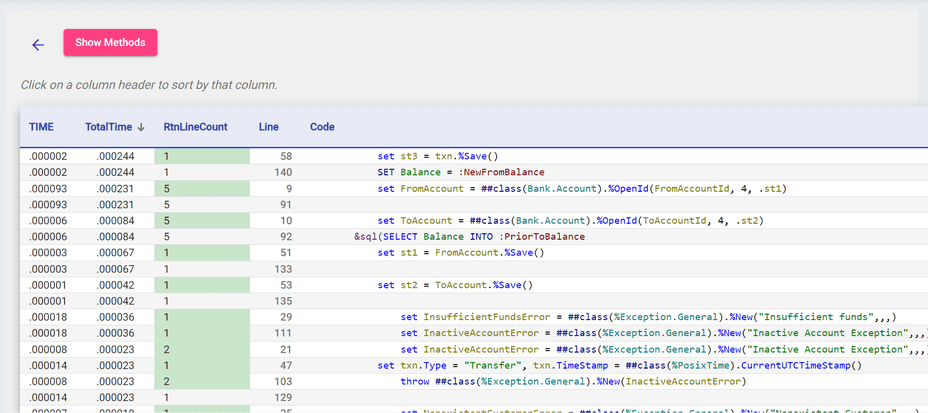
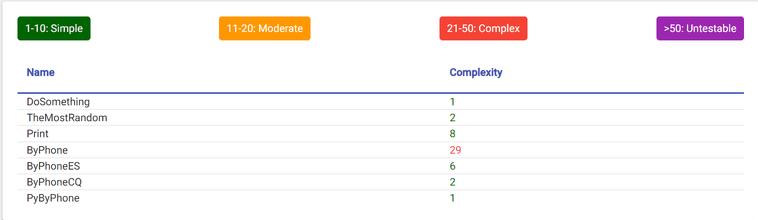
Por fim, o botão "Mostrar Métodos" abre uma tabela com a complexidade ciclomática de cada um dos seus métodos, mostrando quais são os mais complexos e vulneráveis a bugs.
Quando terminar, você pode clicar no botão "Voltar" para retornar à página inicial. O botão vermelho "Limpar resultados" permite apagar todas as suas execuções de cobertura de teste.
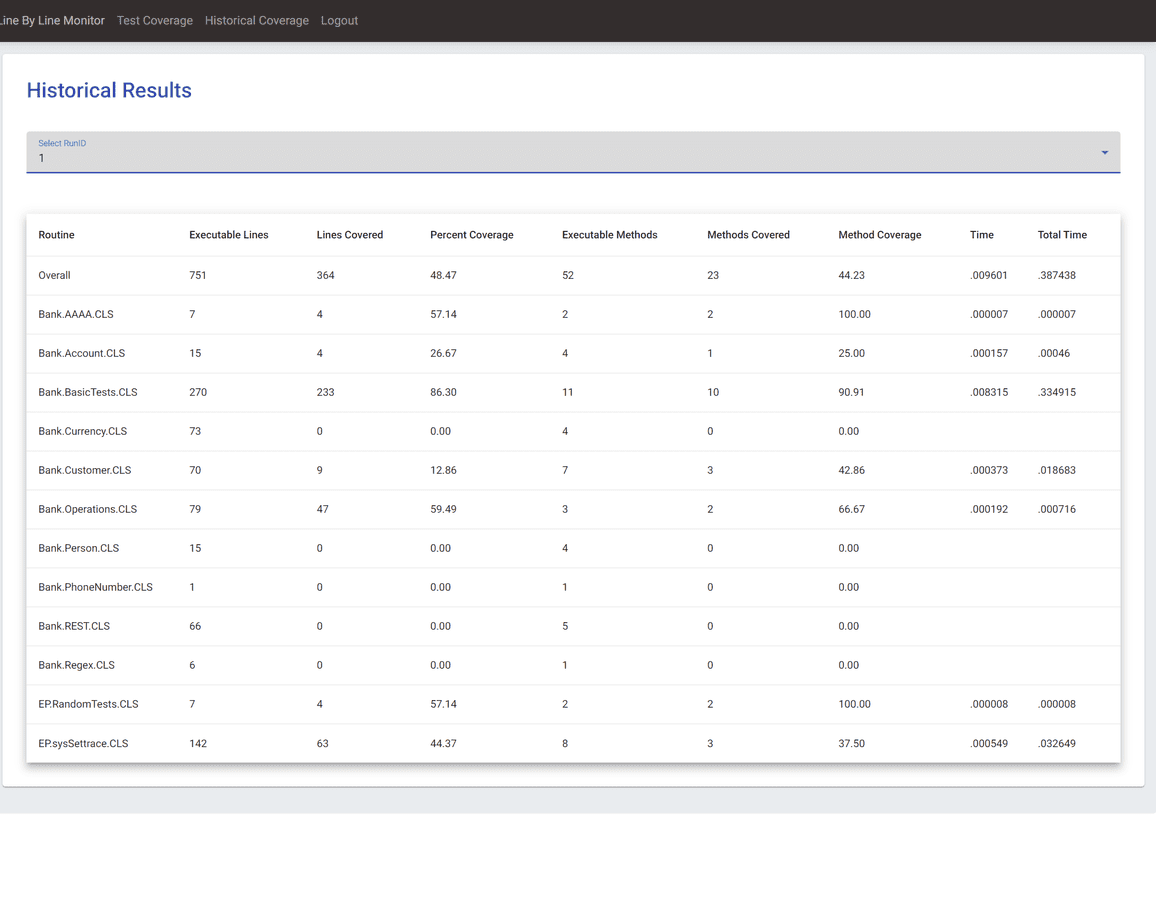
Página de Cobertura Histórica
Após clicar em um ID de Execução específico de uma execução anterior, você pode visualizar os resultados de cobertura em nível de classe (cobertura de linha, cobertura de método, tempo) para todas as classes daquela execução. Estes são os mesmos dados da página de resultados principal do TestCoverage. Esta tabela também é classificável por cada coluna.
Mais uma vez, ambas as ferramentas estão disponíveis no InterSystems Open Exchange (isc-perf-ui e Test Coverage Tool) e no GitHub. Bons testes a todos!

.png)