OEX mapping #2
Technology Strategy
When I started this project I had set myself limits:
Though there is a wide range of almost ready-to-use modules in various languages
and though IRIS has excellent facilities and interfaces to make use of them
I decided to solve the challenge "totally internal" just with embedded Python, SQL, ObjectScript
Neither Java, nor Nodes, nor Angular, PEX, ... you name it.
The combination of embedded Python and SQL is preferred. ObjectScript is just my last chance.
I was especially impressed how easy reading an HTTPS page with Python was.
On the other hand, I left Unit Test and Global Merge and Object Property Setter in COS
Add on after 1st release
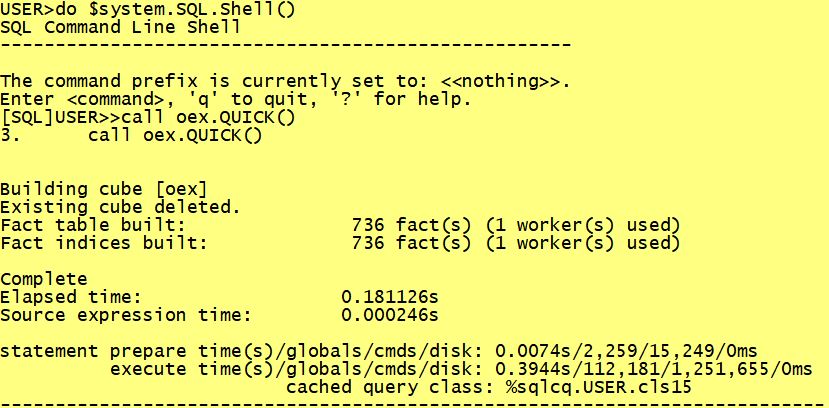
The fact that the initial load took about 50 min was rather shocking to have 730 records in the end.
So kind of a QUICK preload was added. In practical work only the first page and eventually during a contest
the 2nd page of the directory holds new entries. The rest is almost static, not to say frozen.
Loading a page 1 and 2 is mostly sufficient to get all new packages
Then loading DETAILS for the few newbies is not worth mentioning.
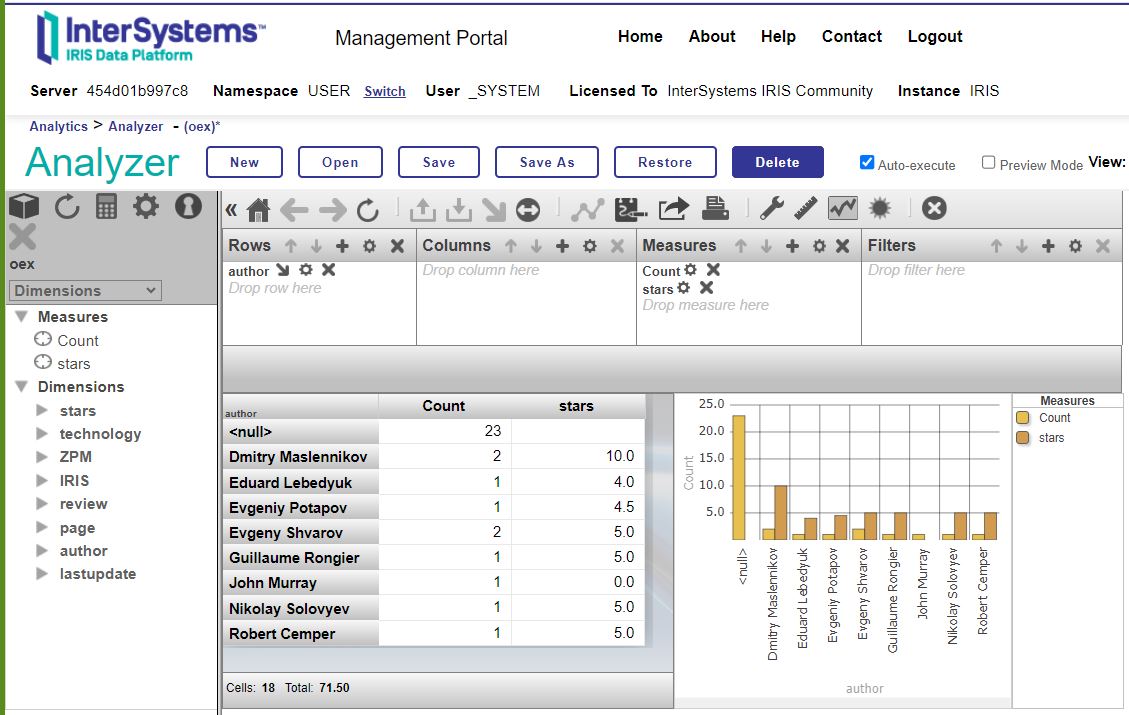
Collecting results with SQl is an easy exercise but pivoting a cube is a bit more comfortable
So I added today classic IRIS Analytics to my package.
It's enabled in Namespace USER and is named OEX similar to the first Pivot to start with
After starting the container the Unit Test leaves a test set of page 1 with ~30 records
Which is also the initial content of the Cube.
 -
-
If you decide to run a completely fresh load it is up to you to rebuild the cube in Analytics Architect.
While using the QUICK variant the final step is a rebuild of the cube and you get this result.
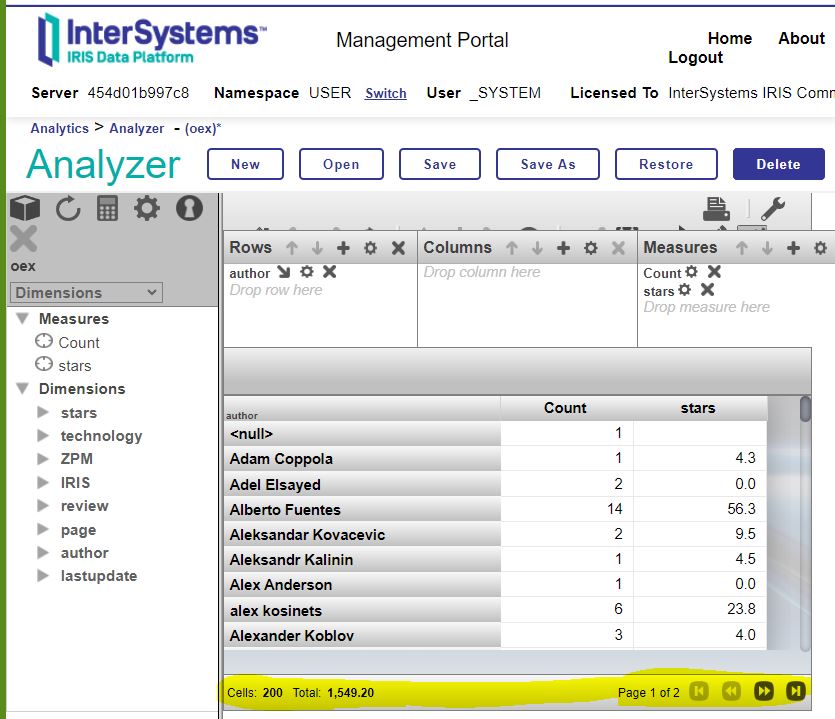
So whether you intend to use SQL or Analytics is your decision.
I count on your votes in the contest