The 3rd Generation of Agents: How "Harness Engineering" Changed Games Again
In last post I talked about iris-copilot, an apparent vision that in near future any human language is a programming language for any machines, systems or products. Its agent runners were actually using such so-called 3rd generation of agents. I want to keep/share a detailed note on what it is, for my own convenience as well. It was mentioned a lot times in recent conversations that I was in, so probably worth a note.
Why the leaked 512,000 lines of Claude Code reveal a fundamentally new paradigm — and why your LangGraph workflows are already legacy
We are witnessing a generational leap in AI agents almost by coincidence.
Over the past four years, the AI industry has moved through three distinct generations of agent technology — each representing not merely an incremental improvement, but a fundamental paradigm shift in how we think about AI systems doing real work. The first generation gave us information. The second gave us orchestration. The third generation — which I call Harness Engineering — gives us something qualitatively different: trust.
And the clearest evidence of this shift? It was accidentally published inside an npm package.
The Accidental Blueprint: Claude Code's 512K-Line Leak
On 31 March 2026, Anthropic shipped a routine npm update for @anthropic-ai/claude-code v2.1.88. A missing .npmignore entry meant the package included a 59.8 MB source map — cli.js.map — containing the complete, unobfuscated TypeScript source code of Claude Code. All 512,000 lines across approximately 1,900 files.
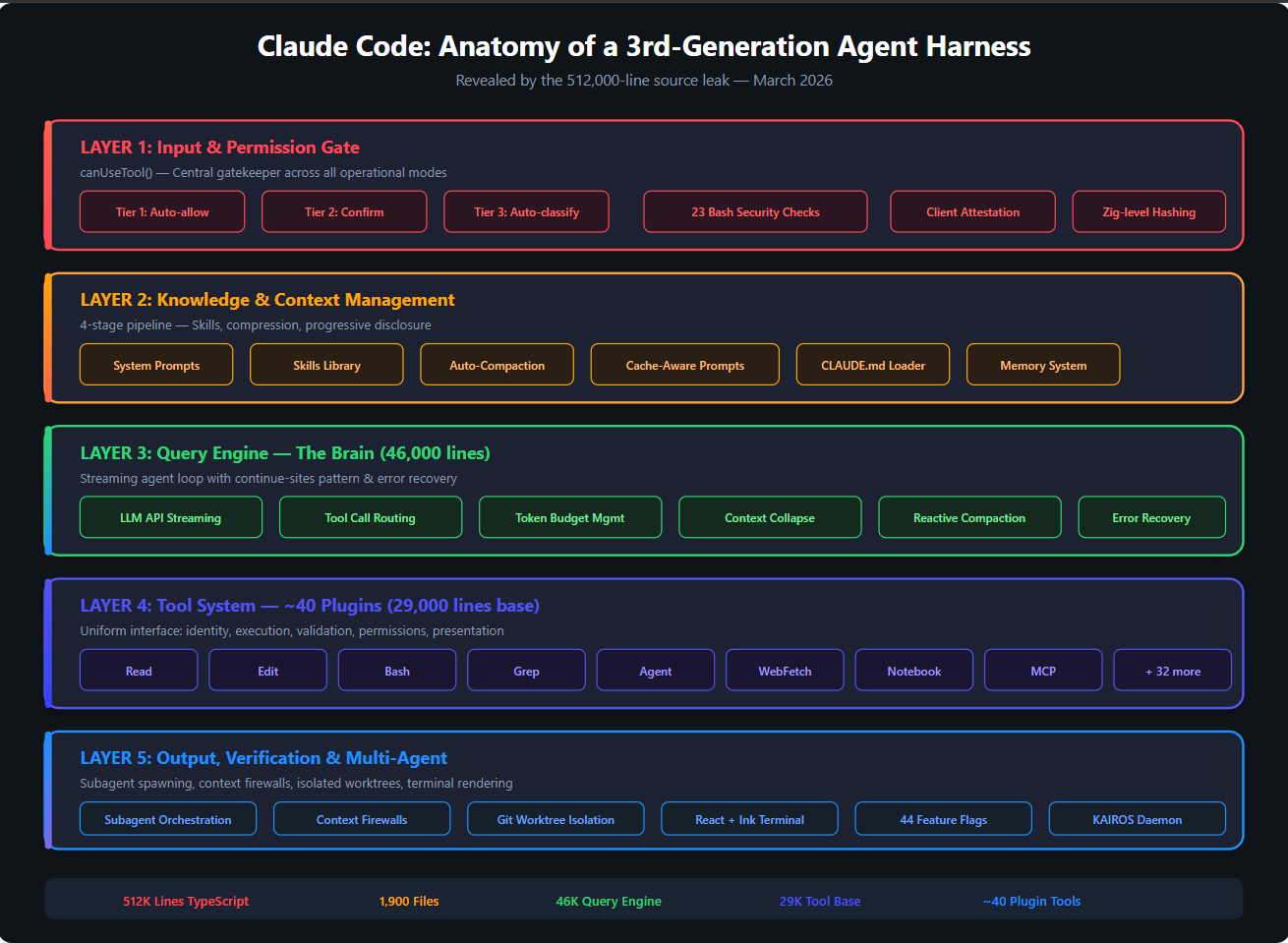
Figure 1: The five-layer architecture of Claude Code's harness, as revealed by the source leak.
Within hours, the code was mirrored, dissected, rewritten in Python and Rust, and studied by tens of thousands of developers. A clean-room rewrite called claw-code hit 50,000 GitHub stars in roughly two hours — likely the fastest-growing repository in GitHub's history.
What made this leak so extraordinary wasn't the code itself. It was what the code revealed about how the most advanced coding agent in the world actually works. And the answer was not what most people expected.
The model is not the moat. The harness is.
The leaked codebase showed a 46,000-line query engine, a 29,000-line tool definition base, approximately 40 modular plugin tools, 44 hidden feature flags, a three-tier permission system, a four-stage context management pipeline, 23 bash security checks, Zig-level cryptographic client attestation, and an unreleased autonomous daemon called KAIROS with nightly memory distillation.
None of this is the LLM. All of it is harness.
Three Generations, so far: A Framework for Understanding
To appreciate why harness engineering represents a genuine paradigm shift, we need to understand the full evolutionary arc.
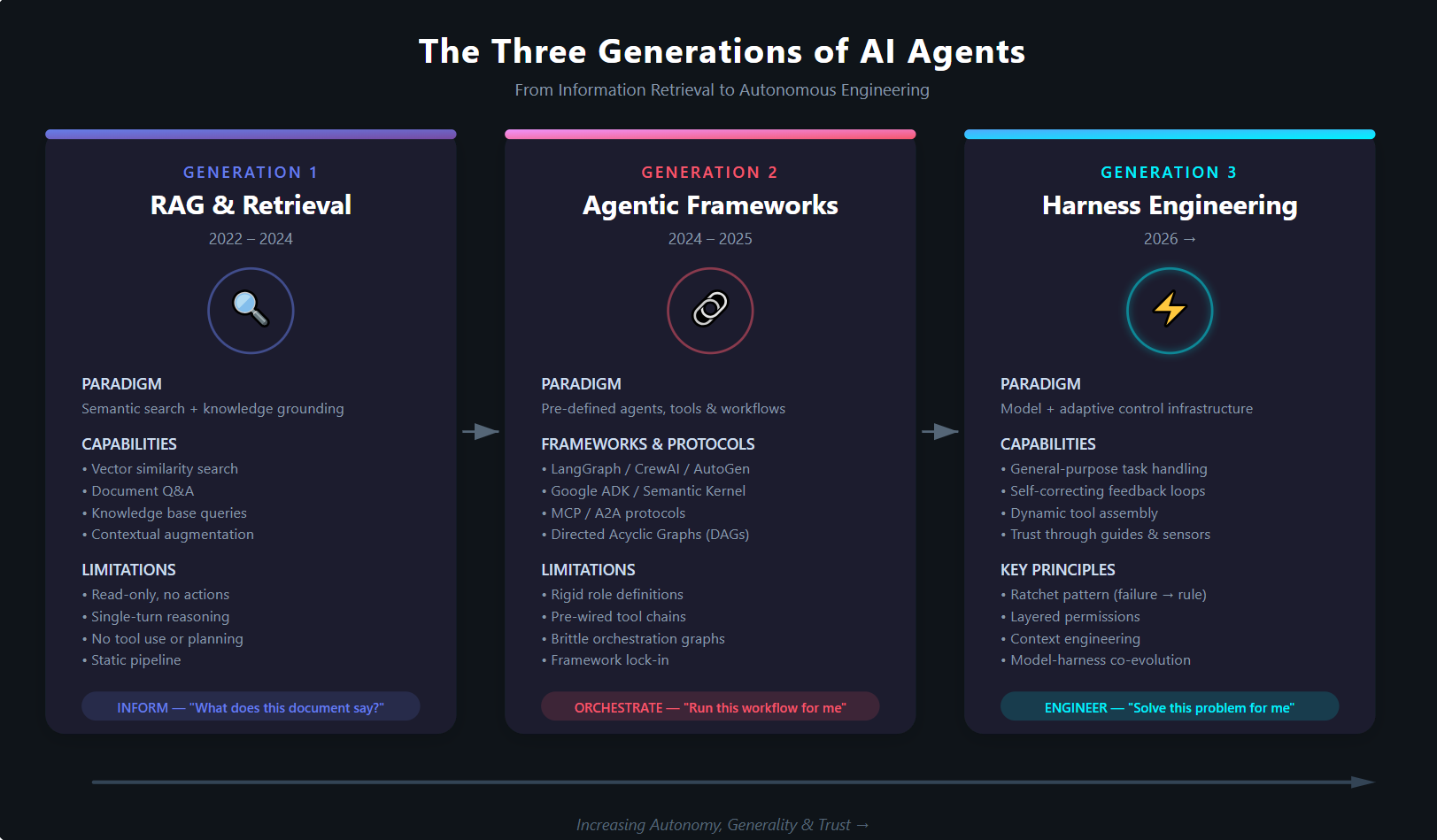
Figure 2: The three generations of AI agents — from semantic retrieval to autonomous engineering.
Generation 1: RAG and Retrieval (2022–2024)
The Paradigm: Semantic information and queries.
The first generation of practical AI applications was built around Retrieval-Augmented Generation. The breakthrough insight was simple but powerful: LLMs have knowledge cutoff dates and hallucinate facts, so ground them in your own data. Vector databases, embedding pipelines, chunking strategies, and retrieval chains became the vocabulary of the field.
RAG solved a genuine problem — making LLMs useful with private, domain-specific information. But it was fundamentally a read-only paradigm. You could ask questions about documents. You could search across knowledge bases. You could generate summaries grounded in real data. What you could not do was act.
The agent in a RAG system is, at best, a very sophisticated search engine with natural language understanding. It retrieves, it synthesises, it responds. It does not create, modify, execute, plan, or recover from failure. There is no feedback loop. There is no tool use. There is no autonomy.
RAG was — and remains — valuable for what it does. But confusing it with agentic AI is like confusing a library catalogue with an engineer.
Generation 2: Agentic Frameworks (2024–2025)
The Paradigm: Pre-defined agents, tools, and workflows.
The second generation emerged when the industry recognised that LLMs could do more than answer questions — they could take actions. Frameworks proliferated: LangGraph, CrewAI, AutoGen, Google's Agent Development Kit (ADK), Semantic Kernel, and dozens more. Protocols like MCP (Model Context Protocol) and A2A (Agent-to-Agent) standardised how agents connect to tools and to each other.
This was a genuine leap. Suddenly you could define a "Research Agent" that searches the web, a "Code Agent" that writes Python, and a "Review Agent" that checks the output — all wired together in a directed acyclic graph. Multi-agent orchestration became possible. Tool calling became a first-class capability.
But there was a catch — and it's a fundamental one.
In every second-generation framework, you must pre-define everything.
You define the agent roles. You define the available tools. You define the workflow graph. You define the state schema. You define the handoff conditions. You define the communication protocols. You write code that says "Agent A calls Tool X, passes the result to Agent B, which calls Tool Y, which decides whether to loop back or terminate."
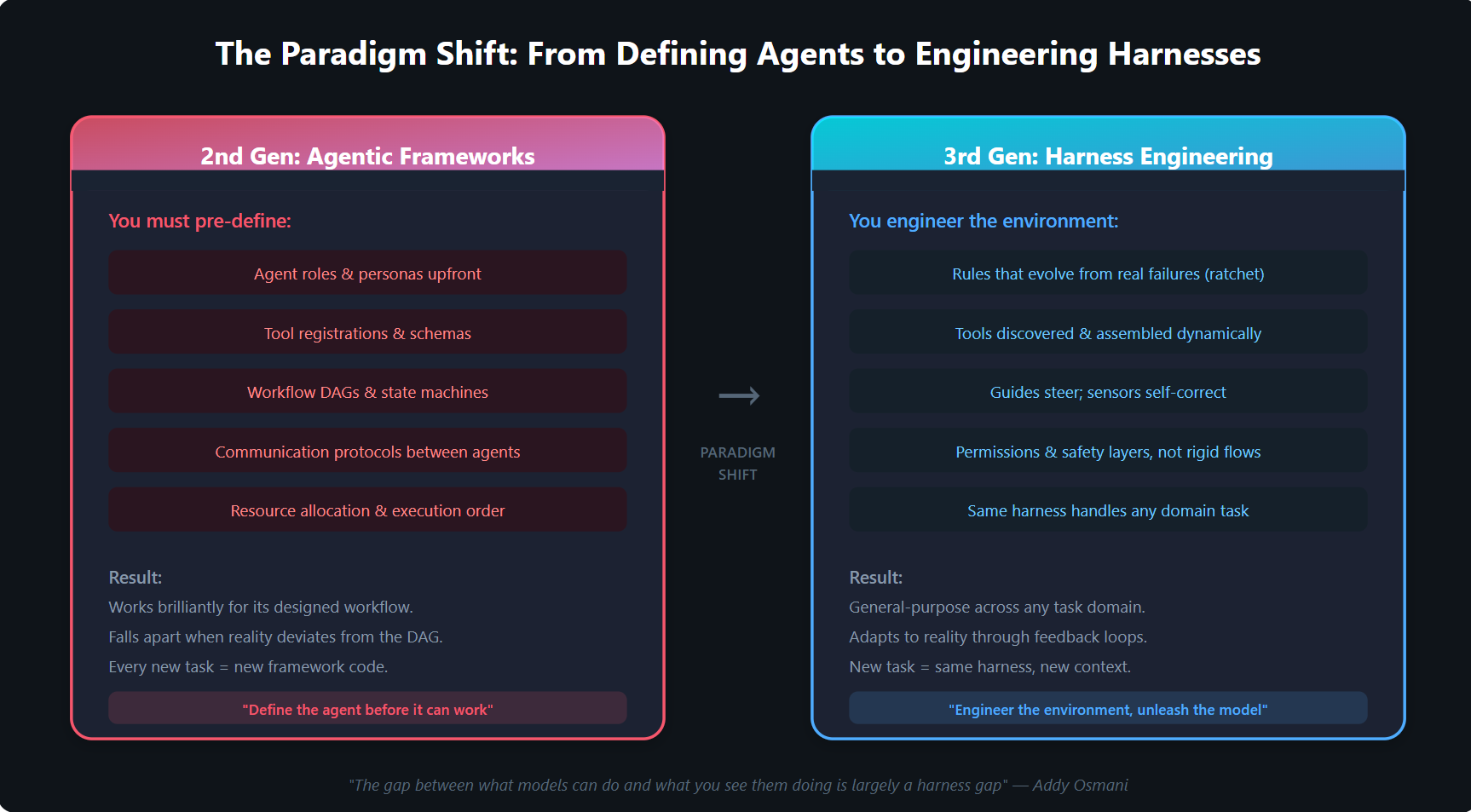
Figure 3: The fundamental difference between 2nd and 3rd generation approaches.
This approach works brilliantly — for the exact workflow you designed it for. But reality is not a DAG. Requirements shift. Edge cases emerge. New tool combinations are needed. And every deviation from the pre-defined graph means writing more framework code.
LangGraph gives you state machines. CrewAI gives you role-based teams. AutoGen gives you conversation patterns. Google ADK gives you function-calling pipelines. MCP gives you a protocol for tool discovery. A2A gives you a protocol for agent communication. All of these are valuable engineering contributions.
But they all share the same fundamental assumption: you, the developer, must architect the agent's behaviour before it runs.
The agent is as rigid as the workflow graph you draw for it. Add a new data source? Register a new tool. Need a different review process? Redesign the DAG. Want the agent to handle an unexpected situation? You can't — not without changing the orchestration code.
This is the "define the agent before it can work" paradigm. And it is already being superseded.
Generation 3: Harness Engineering (2026 →)
The Paradigm: Engineer the environment, unleash the model.
The term "harness engineering" entered mainstream usage in early 2026, catalysed by Birgitta Böckeler's foundational article on martinfowler.com, followed rapidly by perspectives from OpenAI, Addy Osmani, and the revelations from the Claude Code leak.
The core insight is captured in a deceptively simple equation:
Agent = Model + Harness
"If you're not the model, you're the harness." — Viv Trivedy
But what makes this a generational shift — not just a naming convention — is the complete inversion of the design philosophy:
In Gen 2, you define what the agent does. In Gen 3, you define the constraints within which the agent operates — and let the model figure out the rest.
A harness-engineered agent doesn't need a DAG telling it which tool to call next. It has a uniform tool interface (as Claude Code's leak revealed: identity, execution, validation, permissions, presentation) and a permission system that governs what actions are safe. The model decides what to do. The harness decides what's allowed.
A harness-engineered agent doesn't need pre-defined roles for "researcher" and "coder" and "reviewer." It has a single, general-purpose agent loop that can spawn subagents with context firewalls and isolated worktrees when the task demands parallelism.
A harness-engineered agent doesn't need a pre-wired workflow for every possible scenario. It has guides that steer its behaviour before generation and sensors that catch mistakes after generation — creating a self-correcting feedback loop that improves autonomously.
The Harness Engineering Framework
Böckeler's framework provides the theoretical foundation. The Claude Code leak provides the existence proof. Together, they define a new discipline.
Guides and Sensors
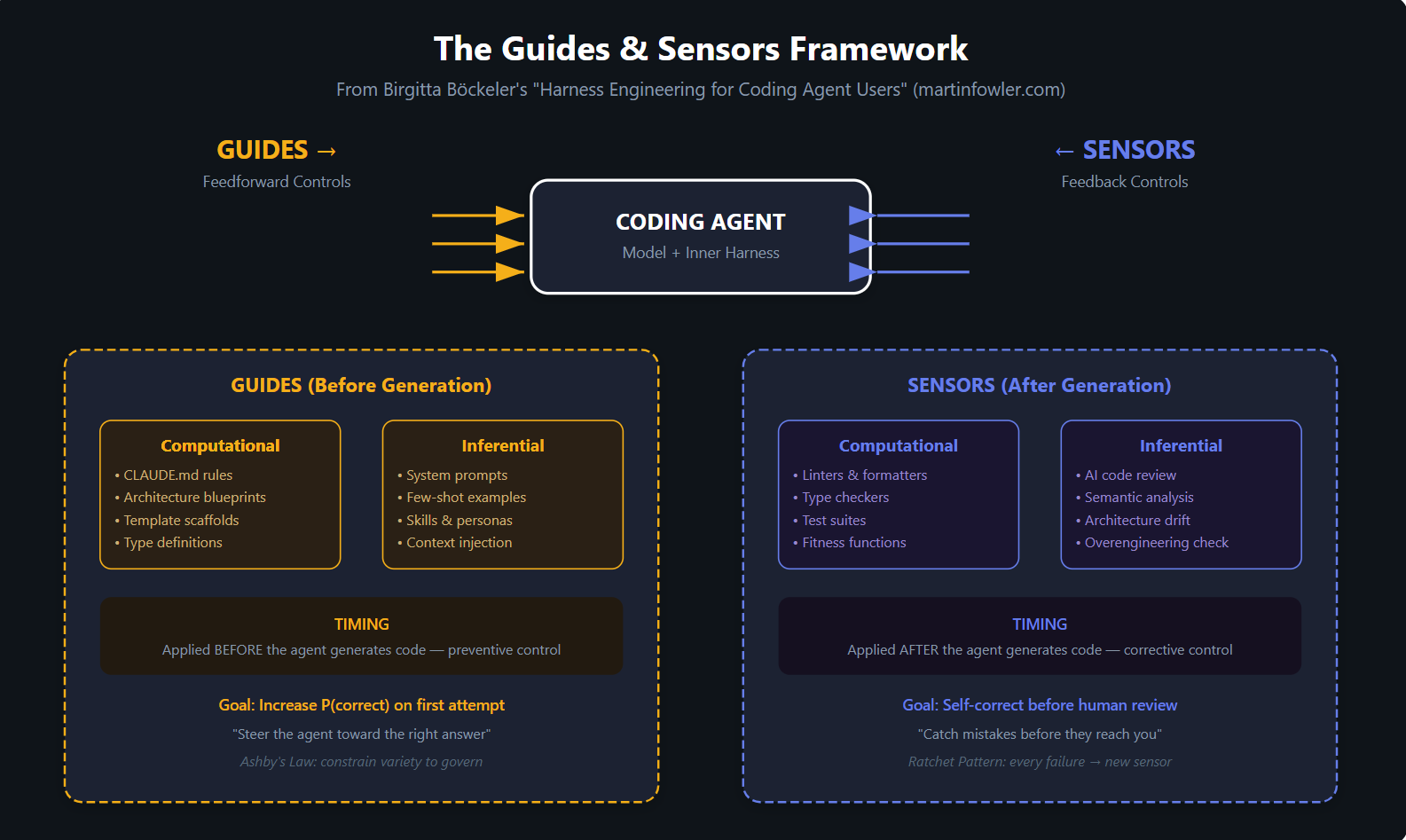
Figure 4: The Guides & Sensors framework — feedforward controls prevent errors, feedback controls catch them.
The framework distinguishes two complementary control mechanisms:
Guides (Feedforward) steer the agent before it generates code. They increase the probability of getting it right on the first attempt. Examples include:
CLAUDE.md/AGENTS.mdfiles with project-specific rules and conventions- Architecture blueprints and template scaffolds
- System prompts with domain-specific knowledge
- Type definitions that constrain the solution space
Sensors (Feedback) observe the agent's output after generation and enable self-correction before human review. Examples include:
- Linters, formatters, and type checkers (computational sensors — fast, deterministic)
- Test suites and fitness functions (computational sensors — reliable but limited)
- AI-powered code review (inferential sensors — slower but semantically rich)
- Architecture drift detection (inferential sensors — catches overengineering)
Both guides and sensors come in two varieties:
- Computational: Deterministic tools that run in milliseconds. Reliable but limited to structural analysis.
- Inferential: AI-based tools that provide semantic judgment. Powerful but probabilistic.
This is not the same as "add a linter to your CI pipeline." The insight is that these controls form a system — an integrated harness that makes the agent progressively more trustworthy through accumulated constraints.
The Ratchet Pattern
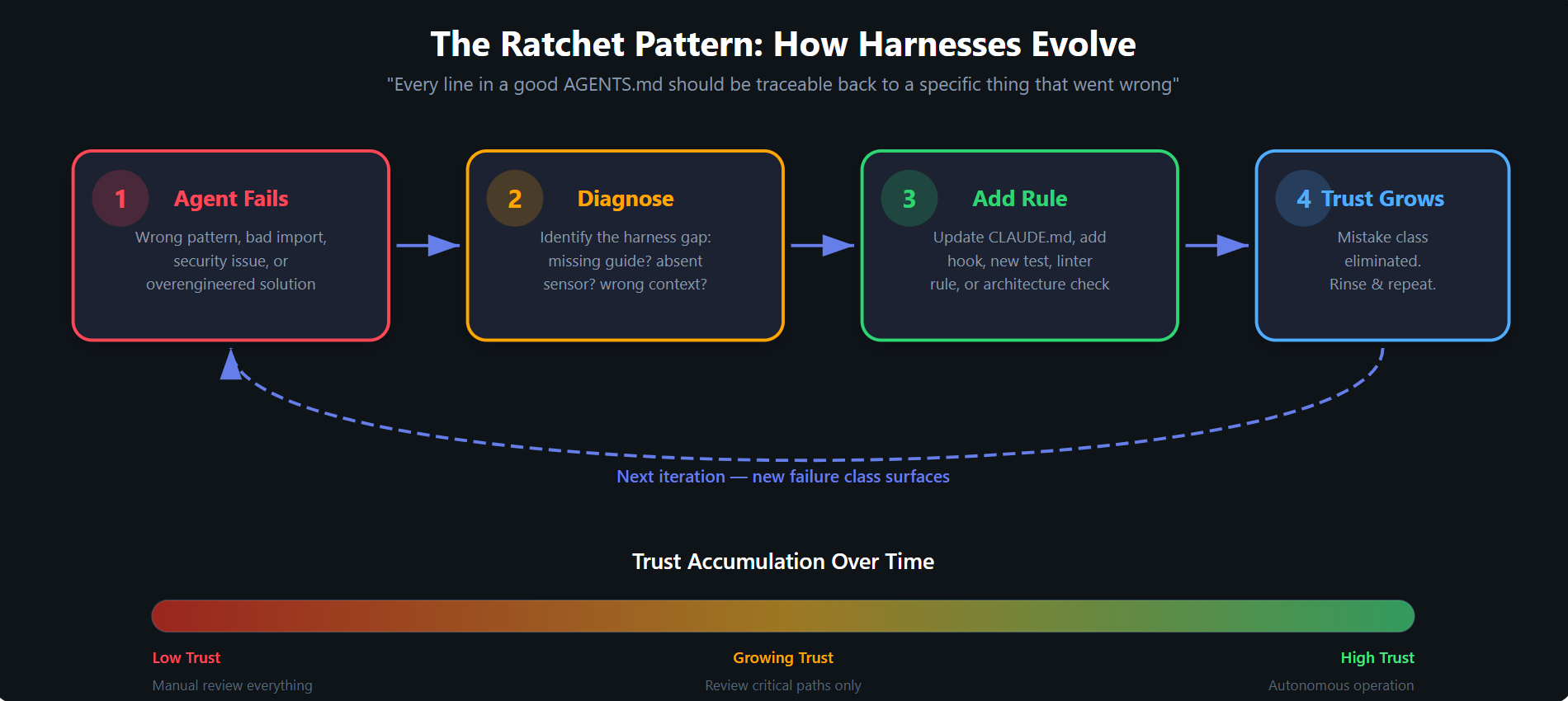
Figure 5: The Ratchet Pattern — trust accumulates through iterative harness improvement.
Perhaps the most important concept in harness engineering is the ratchet pattern: every failure becomes a new rule.
- The agent makes a mistake
- You diagnose the root cause — a missing guide or absent sensor
- You add a constraint to the harness (a new rule in
CLAUDE.md, a new hook, a new test) - That class of mistake is eliminated permanently
- Trust grows; repeat with the next failure class
Over time, the harness accumulates institutional knowledge. Each rule is traceable to a specific incident. The harness becomes a living document of "everything that has gone wrong and how we prevent it from happening again."
This is fundamentally different from tuning prompts or adjusting framework parameters. It's engineering in the traditional sense — building reliable systems through systematic constraint and verification.
The Architecture That Proves It
The Claude Code leak revealed what a mature third-generation harness looks like in production. Five distinct layers, each serving a specific purpose:
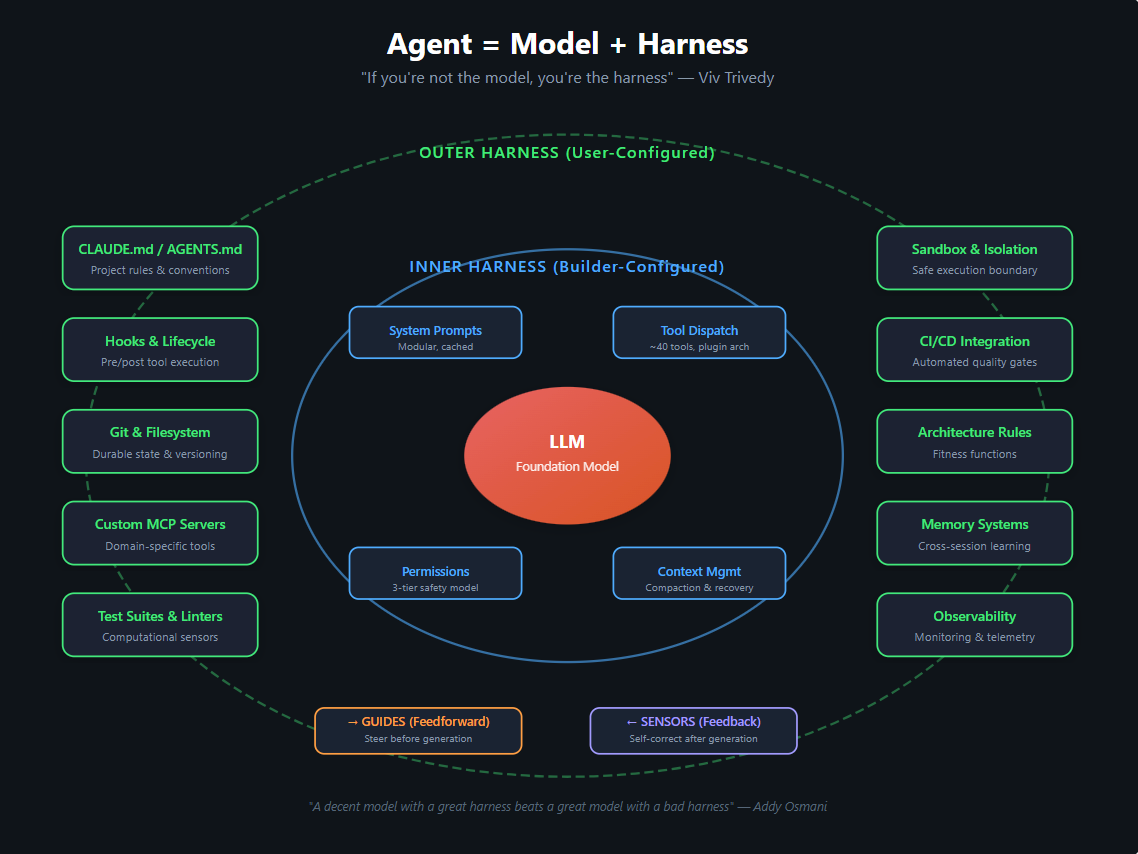
Figure 6: The concentric harness architecture — Model at the core, surrounded by Inner Harness (builder-configured) and Outer Harness (user-configured).
-
Input & Permission Gate —
canUseTool()as central gatekeeper. Three tiers: auto-approved read-only actions, state-modifying actions requiring confirmation, and an automated classifier (running on a separate model instance) that evaluates borderline cases. -
Knowledge & Context Management — A four-stage pipeline with modular system prompts designed for cache efficiency, a skills library with progressive disclosure, auto-compaction that dynamically manages the context window, and persistent memory across sessions.
-
Query Engine — The 46,000-line brain implementing a streaming agent loop with "continue sites" — multiple exit and re-entry points that allow the agent to recover from exhausted output budgets, context overflow, and tool failures without losing progress.
-
Tool System — Approximately 40 tools implementing a uniform interface. Every tool — from simple file reads to complex web searches — shares the same contract: identity, execution, validation, permissions, presentation. New tools plug in without changing the orchestration layer.
-
Output & Multi-Agent — Subagent spawning with context firewalls, isolated git worktrees for parallel work, and a React + Ink terminal rendering engine using game-engine optimisations.
The key observation: none of this is a workflow DAG. There is no pre-defined sequence of "first search, then code, then review." The model decides what to do at each step. The harness decides what's safe and provides the feedback that keeps the model on track.
Why This Matters: The Convergence Evidence
The strongest evidence that harness engineering represents a genuine paradigm shift — not just Anthropic's approach — is the convergence pattern. As Addy Osmani observed, top coding agents (Claude Code, Cursor, Codex, Aider, Cline) converge on similar harness patterns despite different underlying models and different development teams.
They all implement:
- Uniform tool interfaces with permission layers
- Context management with compaction and recovery
- File system and git as durable state
- Bash/shell as a general-purpose execution environment
- Memory systems for cross-session learning
- Hooks for lifecycle enforcement
- Sandboxing for safe execution
This convergence suggests the industry is discovering load-bearing scaffolding principles — structural requirements for any general-purpose agent that works reliably in the real world.
OpenAI's production experience reinforces this. Their Codex team built an application with over one million lines of code where zero lines were written by human hands. Over five months, roughly 1,500 pull requests were opened and merged with a team of just three engineers — an average of 3.5 PRs per engineer per day. The secret was not a better model. It was a better harness.
The Implications for Practitioners
If you're currently building with second-generation frameworks, this analysis is not a call to abandon them tomorrow. LangGraph, CrewAI, and their peers remain excellent tools for well-defined, repeatable workflows where the task structure is known in advance.
But if you're building systems that need to handle general-purpose tasks — the kind where you can't predict every workflow in advance — the third generation offers a fundamentally different approach:
-
Stop defining agents. Start defining constraints. Instead of writing orchestration code that specifies what the agent does, write rules that specify what the agent shouldn't do. Let the model's general intelligence handle the rest.
-
Invest in sensors, not supervisors. Every time you catch yourself manually reviewing agent output, ask: can I build a computational or inferential sensor that catches this automatically?
-
Adopt the ratchet pattern. Keep a living document of agent failures and the rules that prevent their recurrence. Your harness should grow organically from real experience, not from hypothetical scenarios.
-
Design for harnessability. Typed languages, clear module boundaries, established frameworks, and comprehensive test suites make your codebase more amenable to agent control. This is what Böckeler calls "ambient affordances."
-
Think in layers, not flows. Permission gates, context management, tool systems, and feedback loops — not directed graphs with conditional edges.
Looking Forward
The model-harness co-evolution cycle is just beginning. As Osmani notes, models improve at specific actions their training harnesses emphasised. Better harnesses create training signals for better models, which enable better harnesses. This is a positive feedback loop that will accelerate rapidly.
The open frontiers identified by the harness engineering community include:
- Multi-agent coordination on shared codebases without conflict
- Self-healing harnesses where agents analyse their own traces to fix harness failures
- Dynamic harness assembly — tools and context assembled just-in-time rather than pre-configured, moving harnesses closer to compiler behaviour
- Behaviour verification — the underdeveloped frontier where computational sensors alone are insufficient and human judgment remains essential
We're at the beginning of this third generation, not its peak. But the direction is clear: the future belongs not to those who build the best models, nor to those who build the most elaborate frameworks, but to those who engineer the most effective harnesses.
The agent isn't the hard part. The harness is.
References & Further Reading
- Böckeler, B. (2026). "Harness Engineering for Coding Agent Users." martinfowler.com.
- OpenAI. (2026). "Harness Engineering: Leveraging Codex in an Agent-First World." openai.com.
- Osmani, A. (2026). "Agent Harness Engineering." addyosmani.com.
- Kim, A. (2026). "The Claude Code Source Leak: Fake Tools, Frustration Regexes, Undercover Mode, and More."
- Layer5. (2026). "The Claude Code Source Leak: 512,000 Lines, a Missing .npmignore, and the Fastest-Growing Repo in GitHub History."
- Huang, K. (2026). "The Claude Code Leak: 10 Agentic AI Harness Patterns That Change Everything."
- NxCode. (2026). "What Is Harness Engineering? Complete Guide for AI Agent Development."
- HumanLayer. (2026). "Skill Issue: Harness Engineering for Coding Agents."