Pandas for KPIs in InterSystems IRIS BI
Pandas is not just a popular software library. It is a cornerstone in the Python data analysis landscape. Renowned for its simplicity and power, it offers a variety of data structures and functions that are instrumental in transforming the complexity of data preparation and analysis into a more manageable form. It is particularly relevant in such specialized environments as ObjectScript for Key Performance Indicators (KPIs) and reporting, especially within the framework of the InterSystems IRIS platform, a leading data management and analysis solution.
In the realm of data handling and analysis, Pandas stands out for several reasons. In this article, we aim to explore those aspects in depth:
- Key Benefits of Pandas for Data Analysis:
In this part, we will delve into the various advantages of using Pandas. It includes intuitive syntax, efficient handling of large datasets, and the ability to work seamlessly with different data formats. The ease with which Pandas integrates into existing data analysis workflows is also a significant factor that enhances productivity and efficiency.
- Solutions to Typical Data Analysis Tasks with Pandas:
Pandas is versatile enough to tackle routine data analysis tasks, ranging from simple data aggregation to complex transformations. We will explore how Pandas can be used to solve these typical challenges, demonstrating its capabilities in data cleaning, transformation, and exploratory data analysis. This section will provide practical insights into how Pandas simplifies these tasks.
- Using Pandas Directly in ObjectScript KPIs in IRIS:
The integration of Pandas with ObjectScript for the development of KPIs in the IRIS platform is simply a game-changer. This part will cover how Pandas can be utilized directly within ObjectScript, enhancing the KPI development process. We will also explore practical examples of how Pandas can be employed to analyze and visualize data, thereby contributing to more robust and insightful KPIs.
- Recommendations for Implementing Pandas in IRIS Analytic Processes:
Implementing a new tool in an existing analytics process can be challenging. For that reason, this section aims to provide best practices and recommendations for integrating Pandas into the IRIS analytics ecosystem as smoothly as possible. From setup and configuration to optimization and best practices, we will cover essential guidelines to ensure a successful integration of Pandas into your data analysis workflow.
Pandas is a powerful data analytics library in the Python programming language. Below, you can find a few benefits of Pandas for data analytics:
- Ease of use: Pandas provides a simple and intuitive interface for working with data. It is built on top of the NumPy library and provides such high-level data structures as DataFrames, which makes it easy to work with tabular data.
- Data Structures: The principal data structures in Pandas are Series and DataFrame. Series is a one-dimensional array with labels, whereas DataFrame is a two-dimensional table representing a set of Series. These data structures combined allow convenient storage and manipulation of data.
- Handling missing data: Pandas provides convenient methods for detecting and handling missing data (NaN or None). It includes some methods for deleting, filling, or replacing missing values, simplifying your work with real data.
- Data grouping and aggregation: With Pandas it is easy to group data by features and apply aggregation functions (sum, mean, median, etc.) to each data group.
- Powerful indexing capabilities: Pandas provides flexible tools for indexing data. You can use labels, numeric indexes, or multiple levels of indexing. It allows you to filter, select, and manipulate data efficiently.
- Reading and writing data: Pandas supports multiple data formats, including CSV, Excel, SQL, JSON, HTML, etc. It facilitates the process of reading and writing data from/to various sources.
- Extensive visualization capabilities: Pandas is integrated with such visualization libraries as Matplotlib and Seaborn, making it simple to create graphs and visualize data, especially with the help of DeepSeeWeb through integration via embedded Python.
- Efficient time management: Pandas provides multiple features for working with time series, including powerful tools for working with timestamps and periods.
- Extensive data manipulation capabilities: The library provides various functions for filtering, sorting, and reshaping data, as well as joining and merging tables, which makes it a powerful tool for data manipulation.
- Excellent performance: Pandas is purposefully optimized to handle large amounts of data. It provides high performance by using Cython and enhanced data structures.
Let's look at an example of Pandas' implementation in an ObjectScript environment. We will employ VSCode as our development environment. The choice of IDE in this case was determined by the availability of InterSystems ObjectScript Extension Pack, which provides a debugger and editor for ObjectScript.
First of all, let's create a KPI class:
Class BI.KPI.pandasKpi Extends %DeepSee.KPI
{
}
Then, we should make an XML document defining the type, name, and number of columns and filters of our KPI:
XData KPI [ XMLNamespace = "http://www.intersystems.com/deepsee/kpi" ]
{
<!-- 'manual' KPI type will tell DeepSee that data will be gathered from the class method defined by us-->
<kpi name="MembersPandasDemo" sourceType="manual">
<!-- we are going to need only one column for our KPI query -->
<property columnNo="1" name="Members" displayName="Community Members"/>
<!-- and lastly we should define a filter for our members -->
<filter name="InterSystemsMember"
displayName="InterSystems member"
sql="SELECT DISTINCT ISCMember from Community.Member"/>
</kpi>
}
The next step is to define the python function, write the import, and create the necessary variables:
ClassMethod MembersDF(sqlstring) As %Library.DynamicArray [ Language = python ]
{
# First of all, we import the most important library in our script: IRIS.
# IRIS library provides syntax for calling ObjectScript classes.
# It simplifies Python-ObjectScript integration.
# With the help of the library we can call any class and class method, and
# it returns whatever data type we like, and ObjectScript understands it.
import iris
# Then, of course, import the pandas itself.
import pandas as pd
# Create three empty arrays:
Id_list = []
time_list = []
ics_member = []
Next step: define a query against the database:
# Define SQL query for fetching data.
# The query can be as simple as possible.
# All the work will be done by pandas:
query = """
SELECT
id as ID, CAST(TO_CHAR(Created, 'YYYYMM') as Int) as MonthYear, ISCMember as ISC
FROM Community.Member
order by Created DESC
"""
Then, we need to save the resulting data into an array group:
# Call the class specified for executing SQL statements.
# We use embedded Python library to call the class:
sql_class = iris.sql.prepare(query)
# We use it again to call dedicated class methods:
rs = sql_class.execute()
# Then we use pandas directly on the result set to make dataFrame:
data = rs.dataframe()
We also can pass an argument to filter our data frame.
# Filter example
# We take an argument sqlstring which, in this case, contains boolean data.
# With a handy function .loc filtering all the data
if sqlstring is not False:
data = data.loc[data["ISC"] == int(sqlstring)]
Now, we should group the data and define x-axis for it:
# Group data by date displayed like MonthYear:
grouped_data = data.groupby(["MonthYear"]).count()
Unfortunately, we cannot take the date column directly from grouped data DataFrame,
so, instead, we take the date column from the original DataFrame and process it.
# Filter out duplicate dates and append them to a list.
# After grouping by MonthYear, pandas automatically filters off duplicate dates.
# We should do the same to match our arrays:
sorted_filtered_dates = [item for item in set(data["MonthYear"])]
# Reverse the dates from left to right:
date = sorted(sorted_filtered_dates, reverse=True)
# Convert dict to a list:
id = grouped_data["ID"].id.tolist()
# Reverse values according to the date array:
id.reverse()
# In order to return the appropriate object to ObjectScript so that it understands it,
# we call '%Library.DynamicArray' (it is the closest one to python and an easy-to-use type of array).
# Again, we use IRIS library inside python code:
OBJIDList = iris.cls('%Library.DynamicArray')._New()
OBJtimeList = iris.cls('%Library.DynamicArray')._New()
# Append all data to DynamicArray class methods Push()
for i in date:
OBJtimeList._Push(i)
for i in ID:
OBJIDList._Push(i)
return OBJIDList, OBJtimeList
}
Next step is to define KPI specific method for DeepSee to understand what data to take:
// Define method. The method must always be %OnLoadKPI(). Otherwise, the system will not recognise it.
Method %OnLoadKPI() As %Status
{
//Define string for the filter. Set the default to zero
set sqlstring = 0
//Call %filterValues method to fetch any filter data from the widget.
if $IsObject(..%filterValues) {
if (..%filterValues.InterSystemsMember'="")
{
set sqlstring=..%filterValues.%data("InterSystemsMember")
}
}
//Call pandas function, pass filter value if any, and receive dynamic arrays with data.
set sqlValue = ..MembersDF(sqlstring)
//Assign each tuple to a variable.
set idList = sqlValue.GetAt(1)
set timeList = sqlValue.GetAt(2)
//Calculate size of x-axis. It will be rows for our widget:
set rowCount = timeList.%Size()
//Since we need only one column, we assign variable to 1:
set colCount = 1
set ..%seriesCount=rowCount
//Now, for each row, assign time value and ID value of our members:
for rows = 1:1:..%seriesCount
{
set ..%seriesNames(rows)=timeList.%Get(rows-1)
for col = 1:1:colCount
{
set ..%data(rows,"Members")=idList.%Get(rows-1)
}
}
quit $$$OK
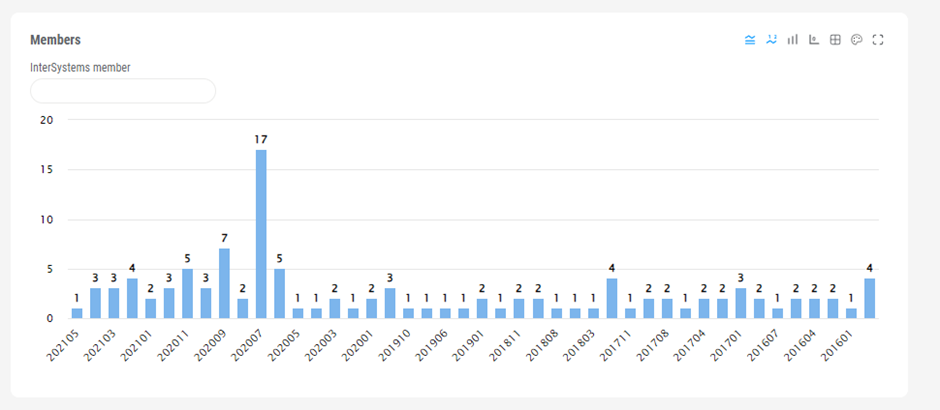
At this point, compile the KPI and create a widget on a dashboard using KPI data source.
That's it! We have successfully navigated through the process of integrating and utilizing Pandas in our ObjectScript applications on InterSystems IRIS. This journey has taken us from fetching and formatting data to filtering and displaying it, all within a single, streamlined function. This demonstration highlights the efficiency and power of Pandas in data analysis. Now, let's explore some practical recommendations for implementing Pandas within the IRIS environment and conclude with insights on its transformative impact.
Recommendations for Practical Application of Pandas in IRIS
- Start with Prototyping:
Begin your journey with Pandas by using example datasets and utilities. This approach helps you understand the basics and nuances of Pandas in a controlled and familiar environment. Prototyping allows us to experiment with different Pandas functions and methods without the risks associated with live data.
- Gradual Implementation:
Introduce Pandas incrementally into your existing data processes. Instead of a complete overhaul, identify the areas where Pandas can enhance or simplify data handling and analysis. It could be some simple tasks like data cleaning aggregation or a more complex analysis where Pandas capabilities can be fully leveraged.
- Optimize Pandas Use:
Prior to working with large datasets, it is crucial to optimize your Pandas code. Efficient code can significantly reduce processing time and resource consumption, which is especially important in large-scale data analysis. Such techniques such as vectorized operations, using appropriate data types, and avoiding loops in data manipulation can significanlty enhance performance.
Conclusion
The integration of Pandas into ObjectScript applications on the InterSystems IRIS platform marks a significant advancement in the field of data analysis. Pandas brings us an array of powerful tools for data processing, analysis, and visualization, which are now at the disposal of IRIS users. This integration not only accelerates and simplifies the development of KPIs and analytics but also paves the way for more sophisticated and advanced data analytical capabilities within the IRIS ecosystem.
With Pandas, analysts and developers can explore new horizons in data analytics, leveraging its extensive functionalities to gain deeper insights from their data. The ability to process and analyze large datasets efficiently, coupled with the ease of creating compelling visualizations, empowers users to make more informed decisions and uncover trends and patterns that were previously difficult to detect.
In summary, Pandas integration into the InterSystems IRIS environment is a transformative step, enhancing the capabilities of the platform and offering users an expanded toolkit for tackling the ever-growing challenges and complexities of modern data analysis.
Comments
What a great case of using Embedded Python in InterSystems IRIS BI! Wonderful, @Evgeniy Potapov !
Do you want to add an Open Exchange app to demo the case? That'd be fantastic!
Awesome!
Do you have dashboard file for this example. If yes, please share the same.
Sure!
You can use or OpenExchange application Demo-Pandas-Analytics
Install it by
zpm "install demo-pandas-analytics"This dashboard is really simple, you can watch the source code here