Vector Search Performance
Test Objectives
InterSystems has been testing Vector Search since it was announced as an “experimental feature” in IRIS 2024.1. The first test cycle was aimed at identifying algorithmic inefficiencies and performance constraints during the Development/QD cycle. The next test cycle used simple vector searches for single threaded performance analysis to model reliable, scalable and performant behaviour at production database scale in IRIS, and performed a series of comparative tests of key IRIS vector search features against PostgreSQL/pgvector. The current test cycle models the expected behaviour of real-world customer deployments using complex queries that span multiple indices (vector and non-vector) and run in up to 1000 concurrent threads. These tests will be run against IRIS, PostgreSQL/pgvector, and ElasticSearch
Test Platform
testing has been carried out on a variety of Linux deployment platforms; at the high end we have utilised the facilities of InterSystems Scalability Lab and our primary test platform has been an HPE bare metal server with 48 cores and 528GB RAM running Ubuntu 24.04 and current versions of IRIS and PostgreSQL/pgvector
Test Data
access to appropriate volumes of high-quality embedding data has been a significant issue during all iterations of testing. Testing during Development and QD phases was typically run against thousands of rows of synthetic (randomly generated) embedding data, production scale testing requires a minimum of one million rows. Synthetic embedding data provides an unsatisfactory basis for production scale testing because it does not support plausibility checking (there’s no source data to validate semantic proximity against) and does not reflect the clustering of data in vector space and its effects on indexed search performance and accuracy (specifically recall). We have used the following datasets during testing:
- 40 thousand embeddings generated from historical bid submissions by the internal RF-Eye project
- reference dataset downloaded from Hugging Face of embeddings generated against Simple Wikipedia articles at paragraph level using the Cohere multilingual-22-12 model, initially 1 million rows and then an additional 9 million rows (out of 35 million available)
- 25 million rows of embeddings generated by a customer against public domain medical data using a custom model
to support our tests data is loaded into a staging table in the database then incrementally moved to vector data structures to support testing at increasing database sizes. Where required indexing is deferred and run as a separate post-move step. A small percentage (generally 0.1%) of the staged data is written to a query data store and subsequently used to drive the test harness; depending on whether we want to model exact vector matching this data may also be written to the vector data store.
We intend to scale our tests up to 500 million rows of embeddings when we can identify and access an appropriate dataset
Test Methodology
our standard vector search unit test performs 1000 timed queries against the vector database using randomly selected (not generated) query parameters. For indexed searches we also run an equivalent unindexed query with the same parameters to establish the ground truth result set, then compute RECALL at 1, 5 and 10 records. Each test run performs one hundred unit tests, and we perform multiple test runs against each configuration/database size
Unindexed Vector Search
in IRIS unindexed COSINE and DOT_PRODUCT search performance demonstrate predictable linear scaling until we reach the compute constraints of the server (typically by exhausting global buffers). Running our test harness against the same dataset in PostgreSQL/pgvector demonstrates that unindexed search is faster in IRIS than in current versions of PostgreSQL/pgvector

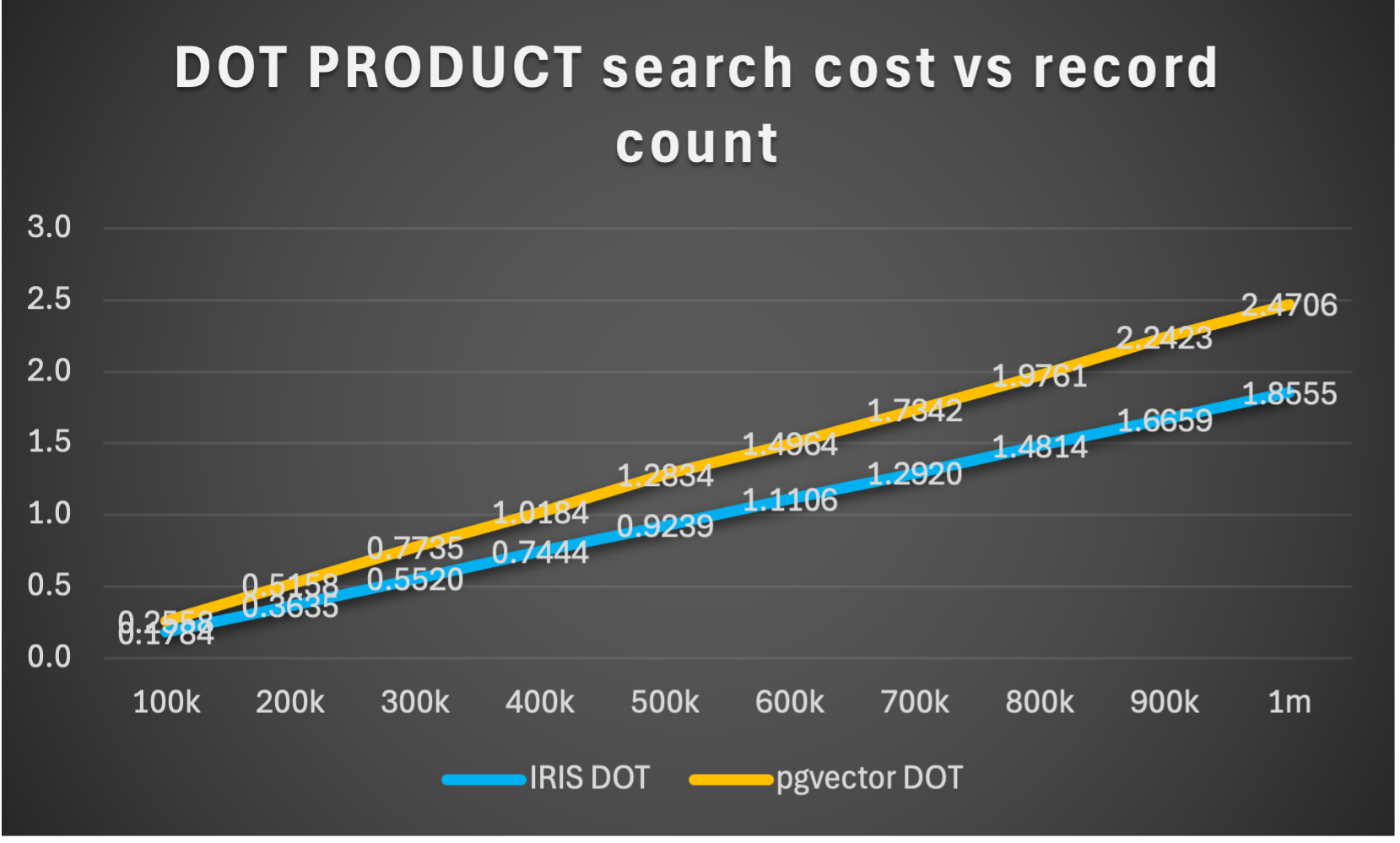
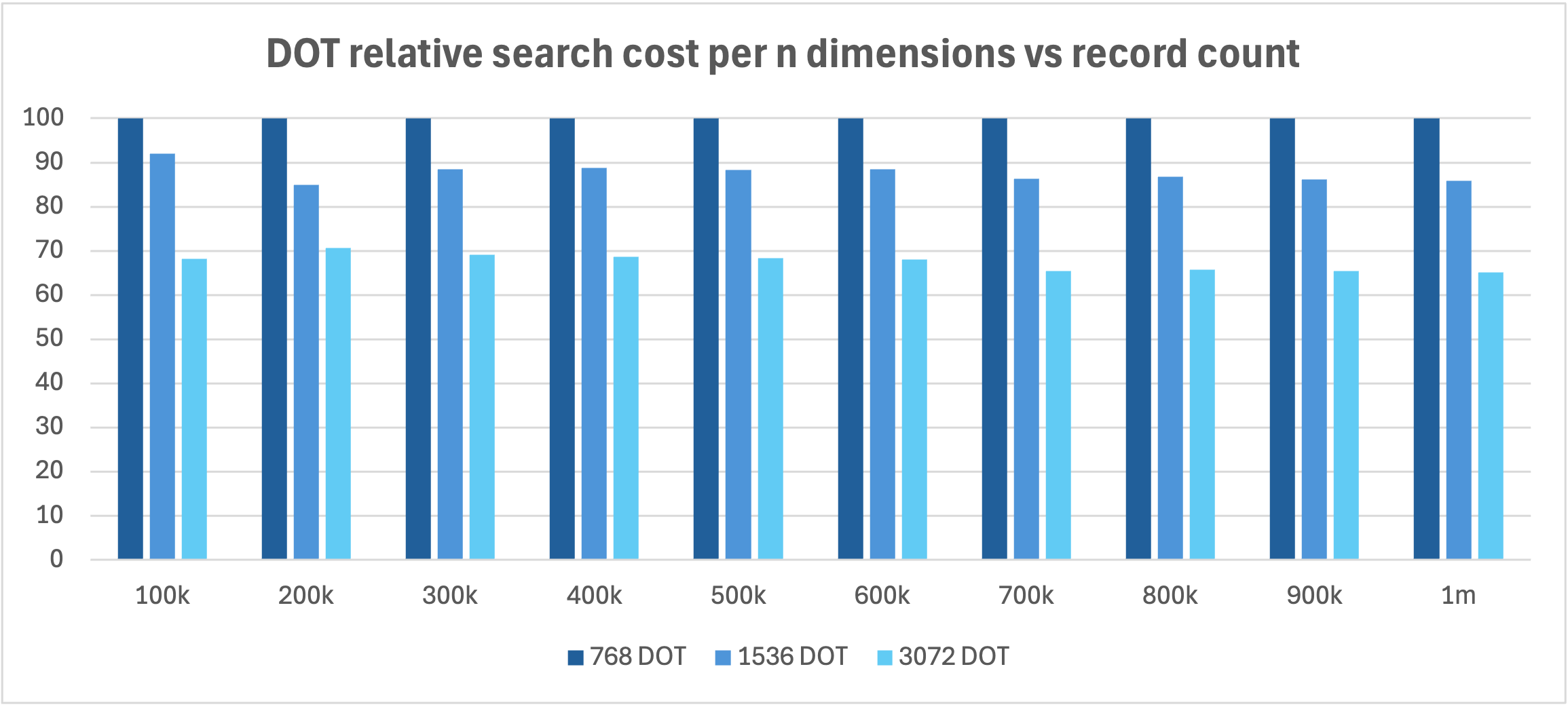
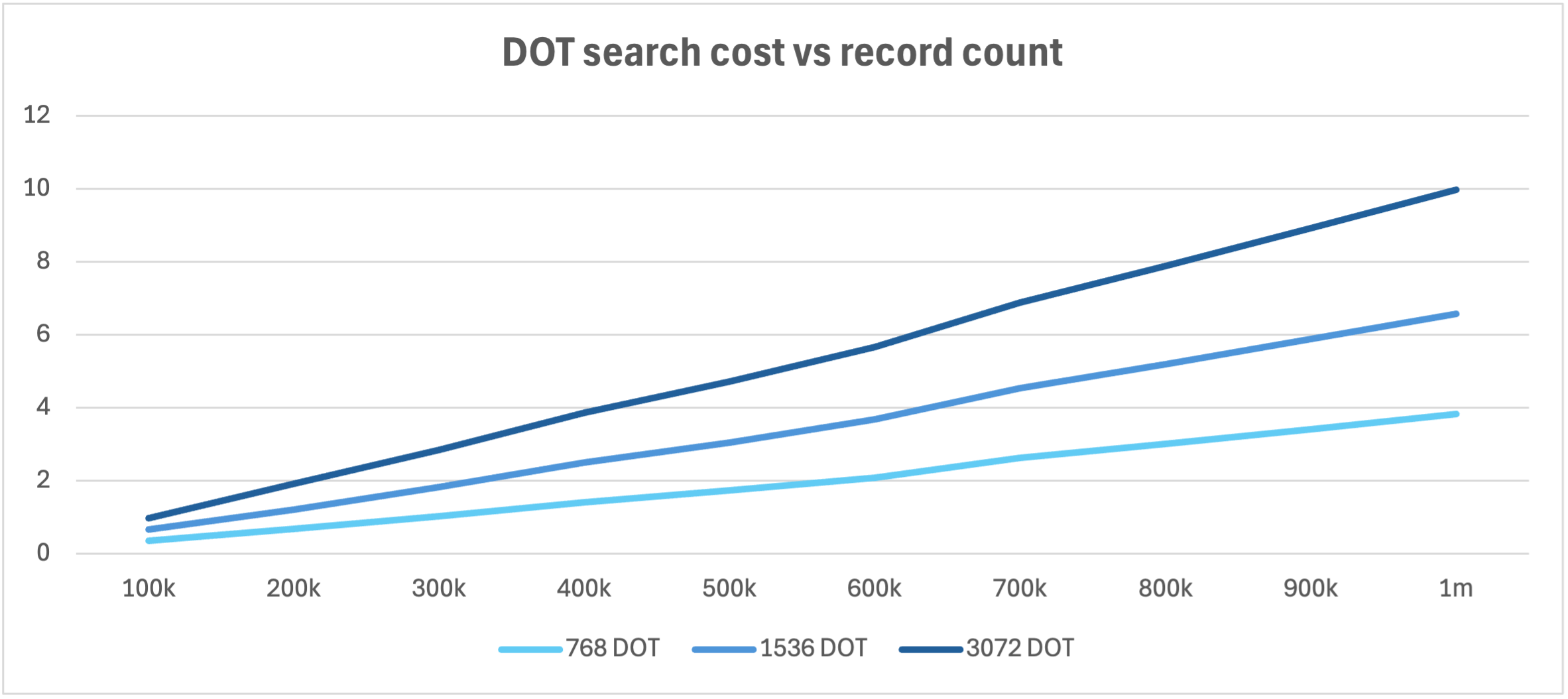
vector storage footprint and unindexed search performance are affected by the dimensionality of the embedding (the number of discrete components that define it in vector space), which is a function of the embedding model. IRIS DOT_PRODUCT and COSINE search cost per n dimensions shows better than linear scaling (the relative cost of searching n dimensions in an embedding decreases as the dimension count of the embedding increases), because the fixed overhead of accessing and processing the record is amortized over a greater number of component calculations
Indexed Vector Search
we have tested Approximate Nearest Neighbor (ANN) search (implemented in IRIS using the Hierarchical Navigable Small World (HNSW) algorithm) with datasets up to 25 million rows of real-world embedding data and 100 million rows of synthetic data.
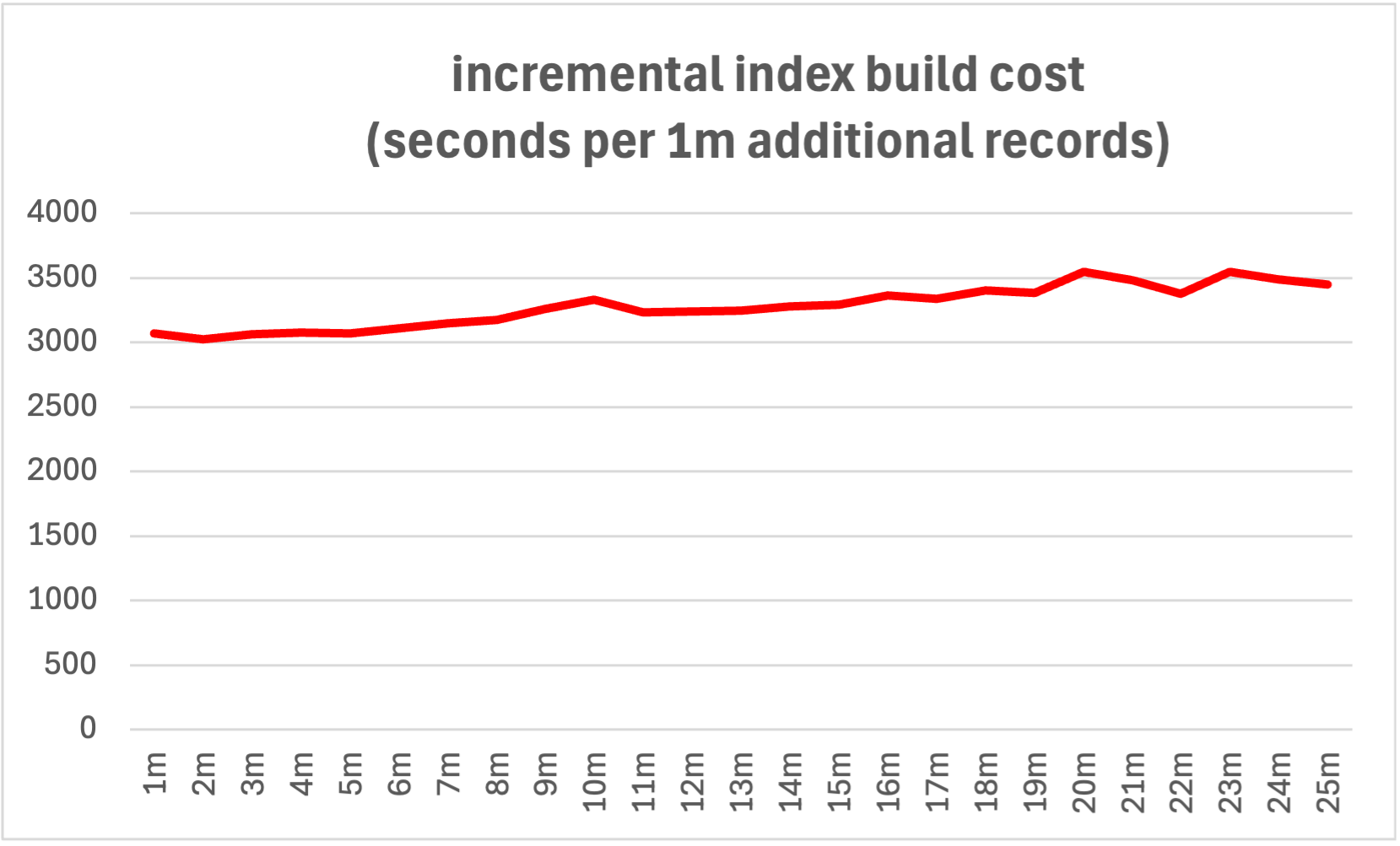
IRIS ANN index build times are predictable and consistent as the number of records being indexed increases, in our test environment (48 core physical server) each increment of 1 million records increases the index build time by around 3000 seconds
IRIS ANN search performance is significantly better than unindexed search performance, with sub-second execution of our test harness at database sizes up to 25 million real world records

ANN search recall was consistently above 90% in our IRIS tests with real world data

comparative testing against the same dataset in PostgreSQL/pgvector demonstrates that IRIS ANN search runs more slowly than an equivalent search in PostgreSQL/pgvector but has a more compact data footprint and quicker index builds
What’s Next?
our current benchmarking effort is focused on complex multi-threaded queries which span multiple indices (ANN and non-ANN). The ANN index is fully integrated into InterSystems query optimizer with an assigned a pseudo-selectivity of 0.5%. The query optimizer generates a query plan by comparing the selectivity of all indices available on the table being queried, with query execution starting with the most selective index and evaluating the ANN index at the appropriate step
Key Application Considerations (so far)
- if you need guaranteed exact results unindexed search is the only option – try to limit the size of the dataset to fit into global buffers for best performance
- restrict dimensionality to the minimum value that will provide the search granularity required by your application (model choice)
- if you’re using ANN indexing understand the RECALL value your application needs and tune the index accordingly (remember this is data dependent)
- the index-time resource requirement is likely to be different from the query-time requirement, you may need different environments
- index build is resource intensive – maximize the number of worker jobs with Work Queue Manager and be aware of the constraints in your environment (IOPS in public cloud); ingest then index rather than index on insert for initial data load
- keep the index global in buffers at query time, consider pre-fetching for optimal performance from first access
- good IRIS system management remains key.