 Globals, these magic swords for storing data, have been around for a while, but not many people can use them efficiently or know about this super-weapon altogether.
Globals, these magic swords for storing data, have been around for a while, but not many people can use them efficiently or know about this super-weapon altogether.
If you use globals for tasks where they truly shine, the results may be amazing, either in terms of increased performance or dramatic simplification of the overall solution (1, 2).
Globals offer a special way of storing and processing data, which is completely different from SQL tables. They were first introduced in 1966 in the M(UMPS) programming language, which was initially used in medical databases. It is still used in the same way, but has also been adopted by some other industries where reliability and high performance are top priorities: finance, trading, etc.
Later M(UMPS) evolved into Caché ObjectScript (COS). COS was developed by InterSystems as a superset of M. The original language is still accepted by developers' community and alive in a few implementations. There are several signs of activity around the web: MUMPS Google group, Mumps User's group), effective ISO Standard, etc.
Modern global based DBMS supports transactions, journaling, replication, partitioning. It means that they can be used for building modern, reliable and fast distributed systems.
Globals do not restrict you to the boundaries of the relational model. They give you the freedom of creating data structures optimized for particular tasks. For many applications reasonable use of globals can be a real silver bullet offering speeds that developers of conventional relational applications can only dream of.
Globals as a method of storing data can be used in many modern programming languages, both high- and low-level. Therefore, this article will focus specifically on globals and not the language they once came from.
 By views
By views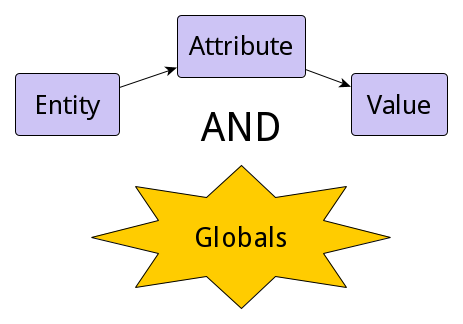
 Open Exchange app
Open Exchange app Beginning -
Beginning -