By update
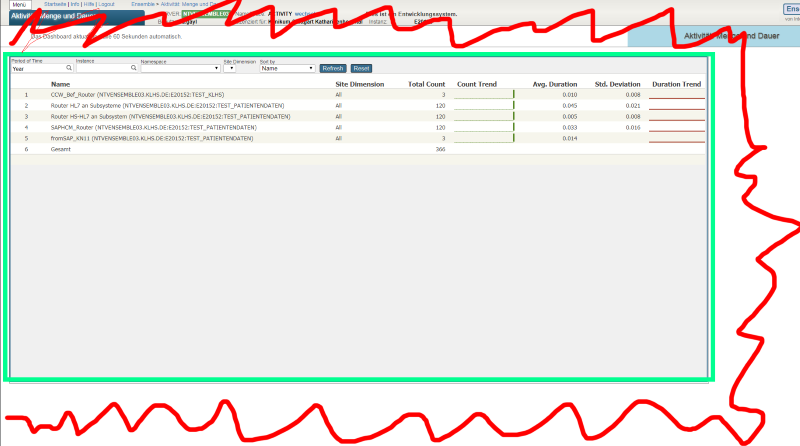
By updateThis post is dedicated to the task of monitoring a Caché instance using SNMP. Some users of Caché are probably doing it already in some way or another. Monitoring via SNMP has been supported by the standard Caché package for a long time now, but not all the necessary parameters are available “out of the box”. For example, it would be nice to monitor the number of CSP sessions, get detailed information about the use of the license, particular KPI’s of the system being used and such. After reading this article, you will know how to add your parameters to Caché monitoring using SNMP.
.png)