In this series of articles, I'd like to present and discuss several possible approaches toward software development with InterSystems technologies and GitLab. I will cover such topics as:
Git 101
Git flow (development process)
GitLab installation
GitLab Workflow
Continuous Delivery
GitLab installation and configuration
GitLab CI/CD
In the first article, we covered Git basics, why a high-level understanding of Git concepts is important for modern software development, and how Git can be used to develop software.
In the second article, we covered GitLab Workflow - a complete software life cycle process and Continuous Delivery.
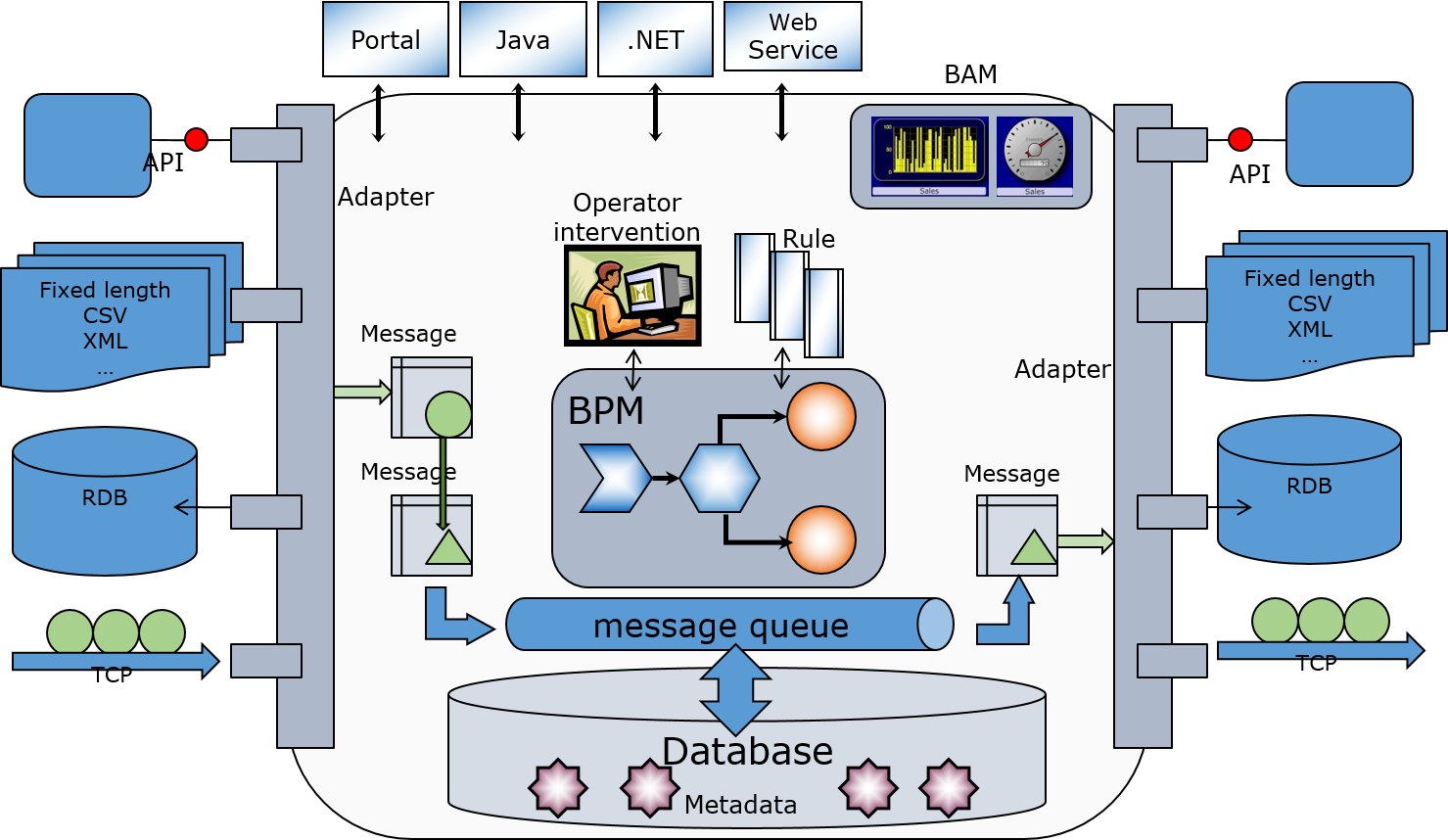
In the previous article, we discussed the development of business processes, which are part of the components required for system integration and serve as a production coordinator.
Often we need to use relatively small arrays with constants, static arrays in algorithms, etc where we need to do something with each element of an array. There are several ways to deal with it in ObjectSctipt.
Previously I used to use globals, locals, PPG for this but not so long time ago figured out that %List is a way too handy.
Indeed, suppose we have an array of months and need to set up and use it in our code.
This series of articles would cover Python Gateway for InterSystems Data Platforms. Execute Python code and more from InterSystems IRIS. This project brings you the power of Python right into your InterSystems IRIS environment:
Recently I was asked, “How can a beginner in InterSystems technologies learn from InterSystems Developers community content to improve his developer skills”?
This is a really good question. It has several answers so I decided to write the post with the hope it could be useful for developers.
So! How to learn Intersystems Data Platforms(IRIS, IRIS for Health) from InterSystems Developers community content if you are a beginner?
How Tax Service, OpenStreetMap, and InterSystems IRIS could help developers get clean addresses
Pieter Brueghel the Younger, Paying the Tax (The Tax Collector), 1640
In my previous article, we just skimmed the surface of objects. Let's continue our reconnaissance. Today's topic is a tough one. It's not quite BIG DATA, but it's still the data not easy to work with: we're talking about fairly large amounts of data. It won't all fit into RAM at once, and some of it won't even fit on the drive (not due to lack of space, but because there's a lot of junk). The name of our subject is FIAS DB: the Federal Information Address System database - the databases of addresses in Russia. The archive is 5.5 GB. And it's a compressed XML file. After extraction, it will be a full 53 GB (set aside 110 GB for extraction). And when you start to parse and convert it, that 110 GB won't be enough. There won't be enough RAM either.
In part 1 we started working on a security model for DeepSee and create a user type having privileges typical of end users. In this part we are going to create a second user type with ability to edit and create DeepSee pivot tables and dashboards.
Trying to evaluate it and work out how we could use it.
As a standard application database. Object or relational etc. does not matter.
Issue is ObjectScript.
So:
1) Can we develop, maintain and use an IRIS database and never use ObjectScript i.e. use only Java, Python, C++ interfaces etc. (exactly which one does not matter)? Would that make designing and using the IRIS database more prone to inefficiency and error?
The following post outlines a more flexible architectural design for DeepSee. As in the previous example, this implementation includes separate databases for storing the DeepSee cache, DeepSee implementation and settings, and synchronization globals. This example introduces one new databases to store the DeepSee indices. We will redefine the global mappings so that the DeepSee indices are not mapped together with the fact and dimension tables.
Has anyone found an Eclipse plug-in that provides the capability to connect to a Caché server and give the user a way to write SQL queries using the tables from that server? I'm picturing something like a "WinSQL"-client built as an Eclipse plugin.
I've found and tried the following, but I couldn't get it to connect to my local Caché instance.
A beginner’s guide to position Ensemble in regards to MicroServices Architecture (MSA). MSA is getting more visibility in the Enterprise Java world therefore it is vital to understand what is behind the buzz. I make a (humble) attempt to write my view and share with you.
NewBie's Corner Session 28 Various Methods to Traverse a Global
Welcome to NewBie's Corner, a weekly or biweekly post covering basic Caché Material.
Judging from the number of responses to Session 27 Traversing A Global, developers are passionate about their methods. I am not here to judge the merit of the various methods.
Over the next few pages I will demonstrate a number of methods to Traverse a Global. If you don't already have a favorite they may help you pick one.
The article is a step by step guide for beginners to learn how to build a RESTful web service consumer (or client) in Ensemble. The provider can be any RESTful service, but the example is based on the service we made during the previous sessions.
We are using object EnsLib.EDI.XML.Document and the method OutputToString -- ( context.XMLObject.OutputToString("C(utf-8)") ), In the string that we get back, Hebrew characters are unknown and we get question mark instead.
 By update
By update

 Open Exchange app
Open Exchange app


.png)